5 Score calculation and correction by the teacher
LabQuiz: A suite of tools for integrating quizzes into Jupyter notebooks
5.1Score calculation¶
A score is calculated automatically for each quiz and displayed in learning and test modes.
An overall score, which is the average of the results on the quizzes taken, can be accessed via quiz.score_global. The score is calculated using the two functions calculate_quiz_score and correct_ans, which are available in the utils and putils modules, respectively. The main principles are as follows:
The function receives the user’s answer user, a weight matrix, and the constraints imposed
weight matrix - the weight matrix is used to weight the answers given according to the expected answer: number of points awarded if the user answered true when the expected answer was true, if they checked true when the expected answer was false, etc. The default matrix is as follows:
default_weights = {
(True, True): 1, # True Positive # Checked and the correct answer was true
(True, False): -1, # False Positive # Checked when the correct answer was false
(False, True): 0, # False Negative # Did not check though the correct answer was true
(False, False): 0 # True Negative # Did not check and the correct answer was indeed false
}In short, here we award one point for correct answers that were checked and deduct one point for correct answers that were not checked. The weight matrix can be specified using the quiz set_weight() method, eg quiz.set_weight(D), where D is a dictionary, with the default above. Depending on the case, we might want to adapt this to penalize correct answers that were not checked, or give less weight to an omission, for example
weights = {
(True, True): 1, # True Positive # Checked and the correct answer was true
(True, False): -0.5, # False Positive # Checked when the correct answer was false
(False, True): -0.5, # False Negative # Not checked when the correct answer was true
(False, False): 0 # True Negative # Not checked and the correct answer was indeed false
}We can also impose an identity weight, which means that we award 1 point for each true statement checked and 1 point for each false statement not checked. A disadvantage of this strategy is that, obviously, a blank copy with no checks gets statistically half the points, if there are as many wrong statements as right ones, or even more if it is a “single correct answer” questionnaire.
weights = {
(True, True): 1, # True Positive # Checked and the correct answer was true
(True, False): 0, # False Positive # Checked when the correct answer was false
(False, True): 0, # False Negative # Did not check when the correct answer was true
(False, False): 1 # True Negative # Did not check and the correct answer was indeed false
}The weight matrix cannot be modified when calculating the score online, but it can be modified when recalculating retrospectively based on the recorded results; see correction by the teacher .
Inside a given question, all propositions have the same weight by default. However it is possible to adjust this using a system of bonus-malus. A proposition can be given a weight (bonus) of 2 while the oter have a weight of one for example. Or a bad answer a malus of -2 while the default is -1. For a given question, the total score is always normalized to 1.
bonus malus - As we have seen in the file structure Section 4.1,
bonusesandpenaltiescan be integrated into the questions themselves. This allows, for a given question, to give more weight to a particular correct answer, or conversely to penalize a wrong answer, independently of the general weighting matrix.logical constraints - Logical constraints can be integrated into questions and used to calculate the score. These constraints are specified question by question in the question file, and penalties are applied if the constraint is violated. The following constraints can be used:
# constraints: List of dictionaries e.g.: [{"indexes" : (0, 1), "type": ‘XOR’, "penalty": 2}]
- XOR (Exclusion) A and B must be different
- IMPLY (Implication) If A is TRUE, then B is TRUE
- SAME (Consistency) A and B are equivalent (same value)
- IMPLYFALSE: If A is TRUE, then B MUST be FALSESee an example at the end of Section 4.1.2.
numerical values - In the case of numerical answers, the difference between the given value and the expected value is calculated. If this difference is less than the threshold defined by the tolerance, the answer is counted as correct[1]. Remember that the tolerance is specified in the question file, and that the greater of the values between tolerance_abs and tolerance_relative*expected is used. If the relative tolerance
tolerancehas not been specified, the value used is 1%. Bonuses (default 1) and penalties (default 0) may also be applied depending on whether the difference between the given value and the expected value is greater or less than the tolerance.
5.2Correction by the teacher¶
In parallel with the practical work, or a posteriori, the teacher can use the automatically recorded results to monitor progress, adjust the weights (weight matrix) or the grading scale. Obviously, this is essential in exam mode, where students do not receive feedback on their answers and where the corrections are not accessible.
To correct all recorded answers, the correction is as simple as:
from labquiz.putils import correctQuizzes
URL = "https:// URL_USED_TO_COLLECT_RESULTS"
SECRET = "SECRET_PASSWORD_SPECIFIED_IN_THE_SHEET"
QUIZFILE = "NAME_OF_QUESTION_FILE.yml" #quiz file CONTAINING the expected values
#
Res = correctQuizzes(URL, SECRET, QUIZFILE)This provides a table of results in the following form
Res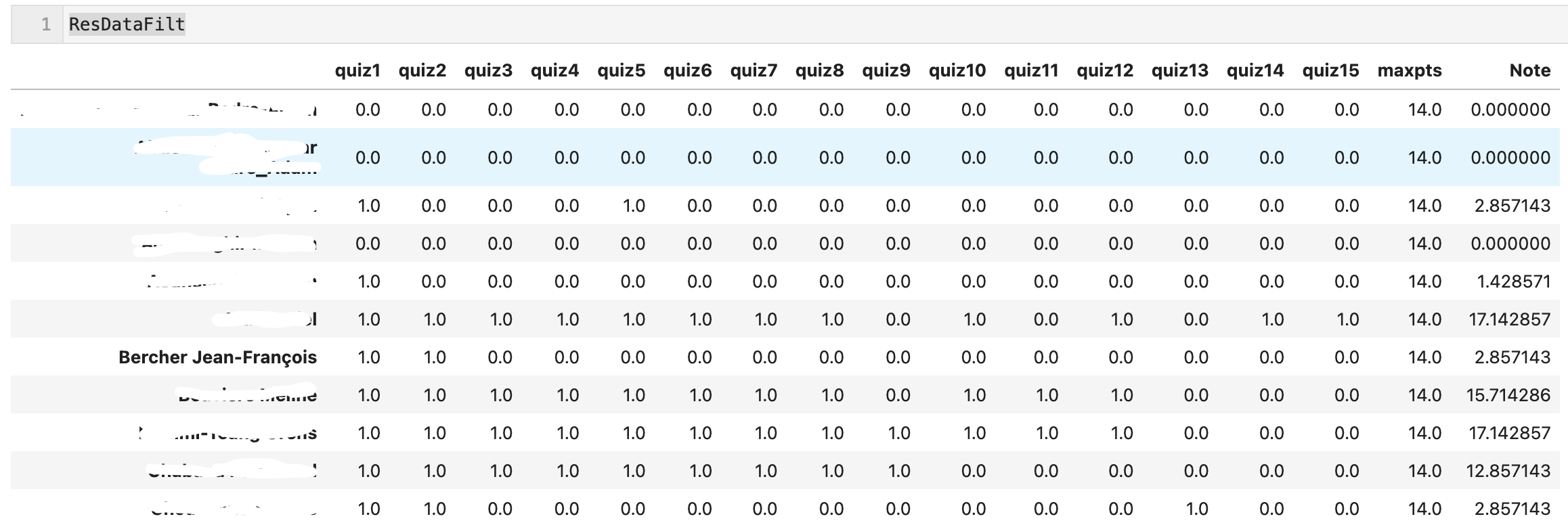
Figure 17:Example of a results table (Students names were masked).
which can of course be exported, for example with
Res.to_csv("Results.csv")5.3Correction for an exam generated with quiz.exam_show()¶
For an exam generated with quiz.exam_show(), which is identified by the title given to it when it was created, the teacher can specifically correct the data collected on the server, according to
(after retrieving the data with readData and instantiating a quiz -- steps 1 and 3 above),
from labquiz.putils import getExamQuestions, getAllStudentsAnswers, correctAll
exam_questions = getExamQuestions("Test to see", data)
students = exam_questions.keys()
students_answers = getAllStudentsAnswers(students, data, maxtries=3)
correctAll (students_answers, quiz, data_filt, threshold=0,
exam_questions=exam_questions, weights=None, marking_scheme=None, maxtries=3)from labquiz.putils import correctQuizzes
URL = "https://URL_USED_TO_COLLECT_AND_STORE_RESULTS"
SECRET = ‘SECRET_PASSWORD_SPECIFIED_IN_THE_SHEET’
QUIZFILE = " NAME_OF_QUESTION_FILE.yml" #quiz file CONTAINING the expected values
Res = correctQuizzes(URL, SECRET, QUIZFILE, title=‘Test title’)where the title of the test to be corrected is specified by the title parameter.
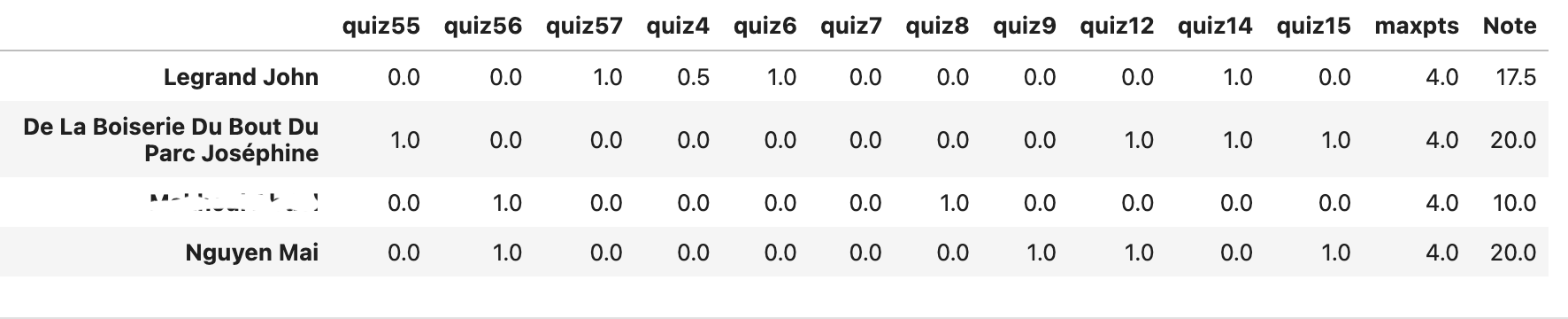
Figure 18:Example of a results table (exam_show).
5.4Correction options¶
Recall that a weighting matrix can be used to assign weights to the four possible response/expected outcome situations encountered in a multiple-choice questionnaire, as shown in . In addition, the different options within a given question can be weighted using a bonus–penalty system. Finally, the overall balance of the questionnaire is adjusted through a global scoring scheme—referred to as “coefficients”—which allows greater weight to be assigned to specific questions, each question initially having a maximum score of 1.
Additional options can be used during correction.
def correctQuizzes(URL, SECRET, QUIZFILE, title=None, threshold=0, weights=None, marking_scheme=None, maxtries=1)title: if title is not None, this indicates that it is the correction of a test with randomly selected questions of type
exam_show, and whose title is title,threshold: threshold=0 sets the scores for each question to zero (otherwise negative scores are possible) ; this is the default value, but if you want to allow negative scores per question, you can set it to -10, for example.
weights: the weight matrix (dictionary) already discussed in Section 5.1
marking_scheme (scale): weight of the different questions in the quiz. If there is no scale, all questions have the same weight for the calculation of the score. If the weight of a question is not specified, it defaults to 1. Example: marking_scheme = {‘quiz3’:4, ‘quiz55’:0} assigns a coefficient of 4 to question quiz3 and neutralizes question quiz55 (all other questions will have a weight of 1),
maxtries: Number of attempts allowed. Correction is performed on the last attempt less than or equal to maxtries (and before any correction request, “Correct” button, if available).
5.5Dashboard¶
During the session, you can retrieve the data table (see previous section) and view the results. The following basic functions allow you to monitor overall progress
# Reading data
URL = "https://URL_UTILISÉE_POUR_RECUEILLIR_LES_RÉSULTATS"
SECRET = "SECRET_PASSWORD_SPECIFIED_IN_THE_SHEET"
data, data_filt = readData(URL, SECRET)
df_last = data_filt.drop_duplicates(
subset=["student", ‘quiz_title’],
keep="last")
#The number of quizzes completed per student
quiz_count_by_student = (
df_last.groupby("student")["quiz_title"]
.apply(len)
.sort_index(ascending=False)
)
# Scores per student
score_by_student = (
df_last.groupby("student")[‘score’]
.apply(np.sum)
.sort_index(ascending=False)
)
# For the entire class
class_counts = (
df_last["quiz_title"]
.value_counts()
.sort_index (
key=lambda idx: idx.str.extract(r"(\d+)").astype(int)[0]
) # alphabetical order
)
#
print("Number of quizzes completed\n\n", quiz_count_by_student)
print("Scores obtained\n\n", score_by_student)
print("Complete class\n\n", class_counts)We can even put this in the form of a small graphical dashboard that we will refresh regularly. The dashboard mentioned above was finally formatted into a dedicated application, which is described in Section 8.1 .
It would be possible to set the score based on the (relative) value of this difference, but this has not been done and is left for “later”.